

We built our omni-channel messaging API on a completely new architecture –microservices. Although microservice architecture is defined differently by different people, since the industry hasn’t agreed on an official definition, Martin Fowler says that it is a “composition via services, organized around business capabilities, products not projects, smart endpoints and dumb pipes, decentralized governance, decentralized data management, infrastructure automation, designed for failure, and evolutionary design.”
Usually, microservices come into the play when monolith applications get too large to manage and common sense says you need to break it down into smaller pieces. Improving the architecture is a captivating and exciting journey, but at the same time complex and easy to mess up.
We learned a few things through our journey in successfully deploying our new API on microservice architecture and wanted to share five common mistakes to avoid during the transition to microservices.
1. Starting too early
First, before beginning, it is important to understand whether you need microservices at all. For relatively small projects, the monolithic approach might be more appropriate, as managing it is much simpler, and microservices introduce a lot of complexities, such as distributed computing and asynchronous communications. But as the project gets larger, you might want to consider the transition to microservices. So, before you begin, make sure that it will bring more benefits than drawbacks.
2. Wrong service boundaries
After making sure that the project needs to transition to microservices, it is important to correctly identify service boundaries. First, you need to understand the domain of your system and then start thinking about boundaries.
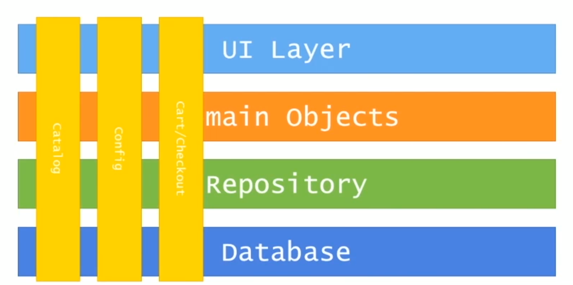
The biggest misstep of service boundaries for microservices is splitting the system into horizontal layers (UI, Business Logic, Data Access Layer, and Database) and then organize the responsibilities vertically, i.e., spanning from the UI all the way down to the database.
The problem with this approach is that new changes affect every tier and updating even small web components will causes a restart of the whole system. Of course, there are some techniques to avoid downtime, but still, compared to microservices, this lacks flexibility.
Additionally, it is important to understand how small the microservice should be. One common mistake is splitting microservices to unnecessary small parts and getting to nanoservices. Nanoservices introduce the overhead of development, deployment, and maintenance that can be avoided by correctly setting boundaries. The golden rule of boundaries is that you should organize around business capabilities.
3. Shared Data
The one big mistake companies usually make is that after implementing microservices they still use a same huge relational database, have shared data, and query multiple tables from outside the service’s responsibilities. Doing this strips us of all the benefits of microservices, and instead we get a distributed monolith.
With the microservices approach, the service should own its data and should not need to query other services to get a result. Having its own database provides the flexibility to choose more appropriate data storage technology, and opt for NoSQL if needed, or stick to relational databases.
4. Automation and monitoring
The next frequent mistake during the transition is that developers usually do not give much attention, or even ignore, automation and monitoring. But without automatic deployment, microservices become unmanageable. To make microservice architecture work, it is very important to be able to deploy swiftly and ideally without any human intervention.
Monitoring is another important aspect of the design. With monolith architecture, when something goes wrong you have a single stack trace, which is easy to debug. On the other hand, it's not that easy with microservices. You need to investigate several different services logs to figure out what is going wrong. Centralized logging and other monitoring tools are a must in microservices.
5. The one-hop rule
And all this leads us to one-hop rule: A service should not call other services to respond to a request; it should be self-contained and manage its own data. Allowing a service to call on other services adds overhead to the request and can result in a very slow or unresponsive service. If you see that you need multiple calls back and forth between several services to synthesize the response, you should consider merging these services into one.
As you may have noticed, all these mistakes are bound together. Failing in one aspect might cause several others, because of the nature of microservices. So, make sure to plan carefully, keep your boundaries straight, automate and monitor early, and don’t forget the one-hop rule.


